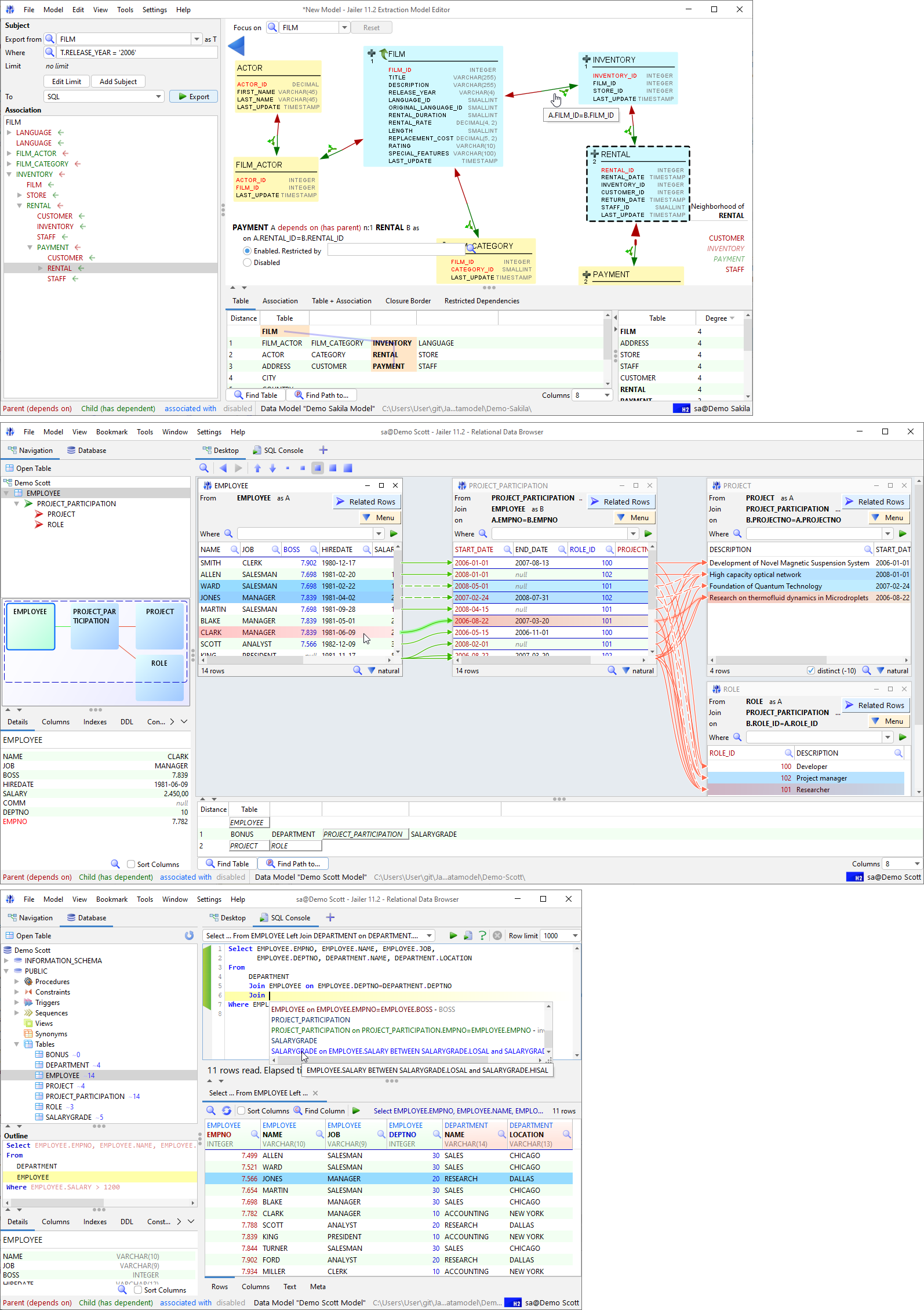
An open source multi-tool for exploring and publishing data
Datasette is a tool for exploring and publishing data. It helps people take data of any shape or size and publish that as an interactive, explorable website and accompanying API.
An open source multi-tool for exploring and publishing data
Datasette is a tool for exploring and publishing data. It helps people take data of any shape or size and publish that as an interactive, explorable website and accompanying API.

I’ve seen this before, and find it truly inspiring and innovative, so I wanted to log it here.
“A communal computer.”
The financials here make absolutely no sense to me, and this is only an example of the current state of (US) economy?
Zoom market cap is currently close to $107 billion, and it announced on July 18. 2021 that it’s acquiring Five9 for $14.7 billion in stock.
Meanwhile, Zoom reported net income of $7.6 million on revenue of $331 million for the year ended January 2020.
(Source)
For sure their success is fascinating, and no small feat, but how is it ever expected that it measures in such a sky high evaluation?
Is the bubble real, or just late capitalism manifestation?
Or are they embodiment of the same religion, capital worshipping on the altar of ever transforming bubble.
The Blue Minds Company, Vienna, Austria
October 2021 – present
Continuing to support The Blue Minds Company in the role of Senior Technology Advisor.
Industry: Energy, Investments
Responsibilities and applied knowledge: Technology analysis, Technical due diligence, Technology Coordination
The Blue Minds Company, Vienna, Austria
October 2019 – October 2021
As the CTO, I was responsible for the technology side of implementing and driving forward the The Blue Minds Company vision in the areas of energy innovation, company building, and consulting.
I oversaw the strategic planning and development of IT by analysing technological innovations in collaboration with the company’s network of solution partners.
Industry: Energy, Investments
Responsibilities and applied knowledge: Technology analysis, Technical due diligence, System integration, Scalability, Cloud, Development process governance, Company process implementation, Provisioning, Hiring
https://github.com/ArchiveBox/ArchiveBox
ArchiveBox is a powerful, self-hosted internet archiving solution to collect, save, and view sites you want to preserve offline.
You can set it up as a command-line tool, web app, and desktop app (alpha), on Linux, macOS, and Windows.
You can feed it URLs one at a time, or schedule regular imports from browser bookmarks or history, feeds like RSS, bookmark services like Pocket/Pinboard, and more. See input formats for a full list.
It saves snapshots of the URLs you feed it in several formats: HTML, PDF, PNG screenshots, WARC, and more out-of-the-box, with a wide variety of content extracted and preserved automatically (article text, audio/video, git repos, etc.). See output formats for a full list.
The goal is to sleep soundly knowing the part of the internet you care about will be automatically preserved in durable, easily accessible formats for decades after it goes down.
Great consideration of necessity for documenting technology decision making. Also, difficulties of culture and mentality changes.
…
…
Compensatory decisions are suitable when time and resources are available to
Non-Compensatory decisions are necessary when
A simple generic code generation tool
Source: ribosome
Joplin
An open source note taking and to-do application with synchronisation capabilities
https://rtpg.co/2021/06/07/changes-checklist.html
Quote:
—
Let’s say you have a web app with some database. In your database you have an Invoice model, where you store things you are charging your customers.
Your billing system is flexible, so you support setting up tax inclusive or exclusive invoices, as well as tax free invoices! In this model you store it as:
class Invoice:
…
is_taxable: bool
is_tax_inclusive: bool
You use this for a couple of years, write a bunch of instances to your database. The one day you wake up and decide that you no longer like this model! It allows for representing invalid state (what would be a non-taxable, but tax-inclusive invoice?). So you decide that you want to go for a new data model:
class TaxType(enum.Enum):
no_tax = enum.auto()
tax_inclusive = enum.auto()
tax_exclusive = enum.auto()
class Invoice:
tax_type: TaxType
You write up this new code, but there’s now a couple problems:
Your database’s data is all in the old shape! You’ll need to move over all your data to this new data model.
You’re a highly available web app! You’re not gonna do any downtime (well, planned, anyways) unless you can’t avoid it.
Your system is spread across multiple machines (high availability right?) so you have to deal with multiple versions of your backend code running at the same time during a deployment.
There’s a whole list of steps you have to do in order to roll out this change. There’s a whole thing about “double writing”, “backfilling” etc. But there’s actually a lot of steps when you end up actually needing to make a backwards-incompatible change!
I feel like I know this list, but every once in a while I end up missing one step when I go off the beaten path, so here’s the list, with every little step required, in all the pedantry.
An important detail here is that you need to roll out each version one-by-one. You can have some parts of your system on Version 3 and others on Version 4. But if you have some of your system on Version 3 and others on Version 5, you will hit issues with data stability. This makes for a lot of steps! Depending on your data model, you might be able to fuse multiple versions into one (especially when you have a flexible system).
Version 0: Read/Write Old Representation
The initial version of your application is using the old model, of course. This is your starting point, and it might not actually be ready for us to start introducing a new model (especially if your application <-> DB layer is particularly strict about what it receives)
Version 1: Can Accept The New Representation
This version will be able to read your data and not blow up if the new representation is present. This doesn’t mean you are using the new representation for anything! Just that you can handle it.
A lot of systems don’t actually require this as a distinct step. You can add a new column to a database and have existing queries continue to work just fiine. But there are a couple places where you need to be more careful. Some examples:
Adding a new value to an enumeration. If I only have tax_inclusive and tax_exclusive, I need to put into place no_tax-handling code before I start migrating data over to this (or having new rows use it).
systems with strict validation. A system might have error paths when a new key starts appearing in some JSON dictionary, so you might need to add preparation code for this.
Migration 1: Add The New Representation To The Database
For an SQL database, this usually is about adding a new column to your database. Some databases might not need this step, and some data model changes might not need this (for example if you are just adding a new value into an enumeration, but the underlying data was stored as a string)
Version 2: Write To Old + New Representation
This version of your application will start filling in both representations on writes to your database. You still continue to read from the old representation (so that writes that happened with V1 of the application still make sense), and writing to the old representation means that during your V1 -> V2 deploy, V1 reads don’t get stale.
Migration 2: Backfill The New Representation In Existing Data
For any rows that haven’t been written to since you rolled out Version 2, you won’t have filled in the new representation of your data (maybe a user just hasn’t logged in for a while!). In order to make sure the new representation is ready to be read, this migration should go through all existing data and fill in the new representation.
You need to do this after Version 2 is deployed, because if a Version 1 write happens during the migration, then the backfilled value will actually be stale. And you need to do this migration before you begin reading the new representation, so that old records can be properly read.
Version 3: Read From The New Representation
You have now filled out the new field, so you can read from it! However, you still need to be writing to both representations. Why? Because Version 2 of your application is still reading from the old field! During a deployment you’ll still have machines on previous versions, so you need to be compatible with coexisting, at least for the duration of a deploy.
Migration 3: Remove Any Mandatory Constraints For Old Representation
This is sometimes not needed, but if you are removing an old field that was once required, you’ll want to remove those constraints at this point. If you don’t do this, then once a version of the app is deployed which removes references to the old version, you will likely hit database constraint failures or the like.
Version 4: Read/Write From The New Representation Only, Remove References To Old Representation
At this point, the previous version was only writing to the old representation for backwards-compatibility reasons. So you can stop writing to the old representation, and have all read/write paths just hit the new one.
At this point you also want to remove references to the old representation (in particular stuff like model fields), in preparation for the final migration.
Migration 4: Drop The Old Representation Entirely
Once you have version 4 out, queries should no longer be referencing the old representation at all. You should be good to go for just dropping this stuff entirely!
This one you gotta be sure though, really hard to roll back this change.
Once you’ve done that you’re good to close out that work!
The Checklist
Deploy Version 1 (Accept New Representation)
Add New Representation To The Database
Deploy Version 2 (Read Old/Write Old + New)
Backfill The New Representation In Existing Data
Deploy Version 3 (Read New/Write Old + New)
Remove Any Mandatory Constraints For The Old Representation
Deploy Version 4 (Read/Write New, Remove References To Old)
Drop The Old Representation Entirely
In your specific case it could be that some of these can be merged. I’ve found that these steps are general enough to cover the most scenarios safely. Though really, the best thing is to really understand why so many steps are needed and whether the characteristics of your system impose different constraints.