Posted on July 28, 2024 by Jan Vlnas
Based on my talk for PragueJS meetup from February 2024
Source: The Web We’ve (Never) Lost
Posted on July 28, 2024 by Jan Vlnas
Based on my talk for PragueJS meetup from February 2024
Source: The Web We’ve (Never) Lost
The Hypertext Transfer Protocol (HTTP) is a stateless application-level protocol for distributed, collaborative, hypertext information systems. This document describes the overall architecture of HTTP, establishes common terminology, and defines aspects of the protocol that are shared by all versions. In this definition are core protocol elements, extensibility mechanisms, and the “http” and “https” Uniform Resource Identifier (URI) schemes. This document updates RFC 3864 and obsoletes RFCs 2818, 7231, 7232, 7233, 7235, 7538, 7615, 7694, and portions of 7230.
Source: RFC 9110: HTTP Semantics
Additional: IETF
https://www.bitoff.org/web-we-never-lost/
Quoting…
This page provides a single entry point to all the posts in the story of how the world got online. The Backbone: Introduction One System, Universal Service? The Unraveling, Part 1 Discovering Inter…

Turns out, a lot of it, actually.
Source: How Much of the Internet Is Fake?
—
The article is from 2018, and I have to confess I didn’t look for more recent statistics, but I can imagine it only got worse. I did a quick of search on this topic, and a lot of articles date from 2018, so it seems the attention just turned to other topics, but I don’t think the actual problem went away.
The Fake Web: How Nonhuman, Fraudulent And Invalid Traffic Is Taking Over The Internet (18 Feb 2022)
The ‘Dead-Internet Theory’ Is Wrong but Feels True – The Atlantic (31 Aug 2021)
All the levels of redirection (Rant 14 Sep 2012)
~
https://github.com/ArchiveBox/ArchiveBox
ArchiveBox is a powerful, self-hosted internet archiving solution to collect, save, and view sites you want to preserve offline.
You can set it up as a command-line tool, web app, and desktop app (alpha), on Linux, macOS, and Windows.
You can feed it URLs one at a time, or schedule regular imports from browser bookmarks or history, feeds like RSS, bookmark services like Pocket/Pinboard, and more. See input formats for a full list.
It saves snapshots of the URLs you feed it in several formats: HTML, PDF, PNG screenshots, WARC, and more out-of-the-box, with a wide variety of content extracted and preserved automatically (article text, audio/video, git repos, etc.). See output formats for a full list.
The goal is to sleep soundly knowing the part of the internet you care about will be automatically preserved in durable, easily accessible formats for decades after it goes down.
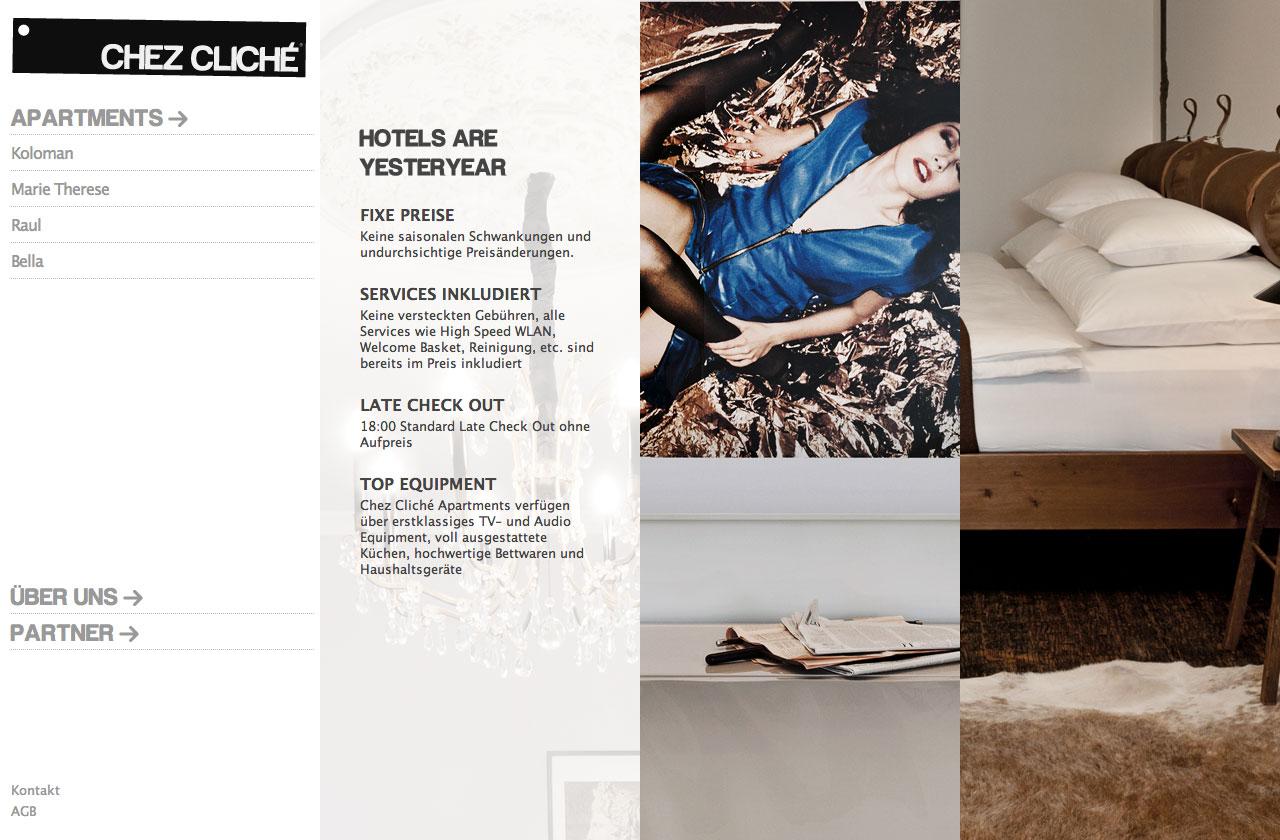
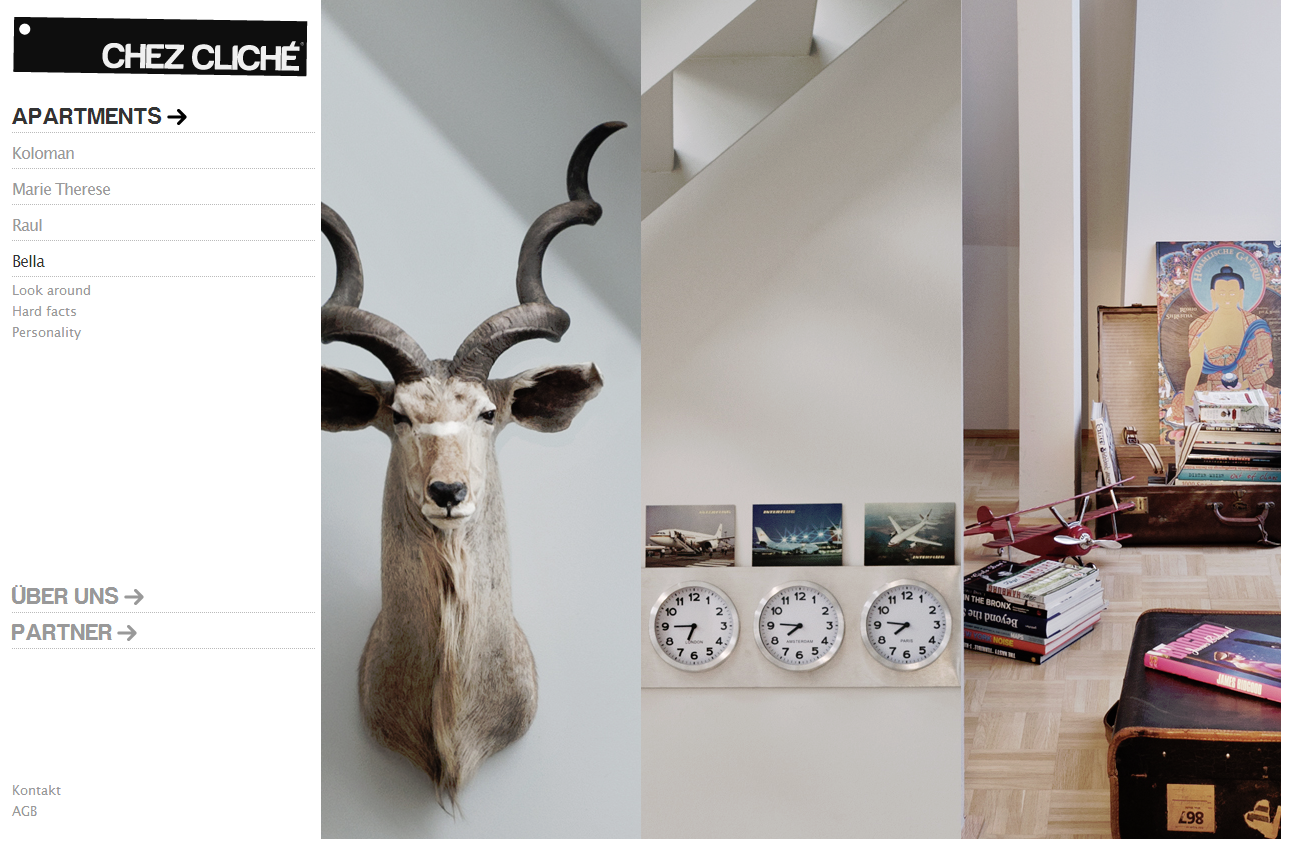
The site was born in close cooperation with fantastic people from CHEZ CLICHÉ Tourismus GmbH.
While trying to convey the atmosphere of the luxurious apartments, I tried to introduce a bit of dynamics with subtle animations.
A special challenge was the third-parti API integration.
Check it out on www.chezcliche.com.

The web is full of redirection these days.
(Warning, a bit of a rant going on here)
I read a lot of content on my phone, and started to notice how much I am redirected around. This is something one usually doesn’t notice on a computer, since the connection is much faster, and I guess the browser renders in a different way.