Before working in an architect role, software quality seemed to me like a very abstract measure, based on ones subjective perception and experience.
While hard to define, there are some attributes commonly used to evaluate quality of a software component or system.
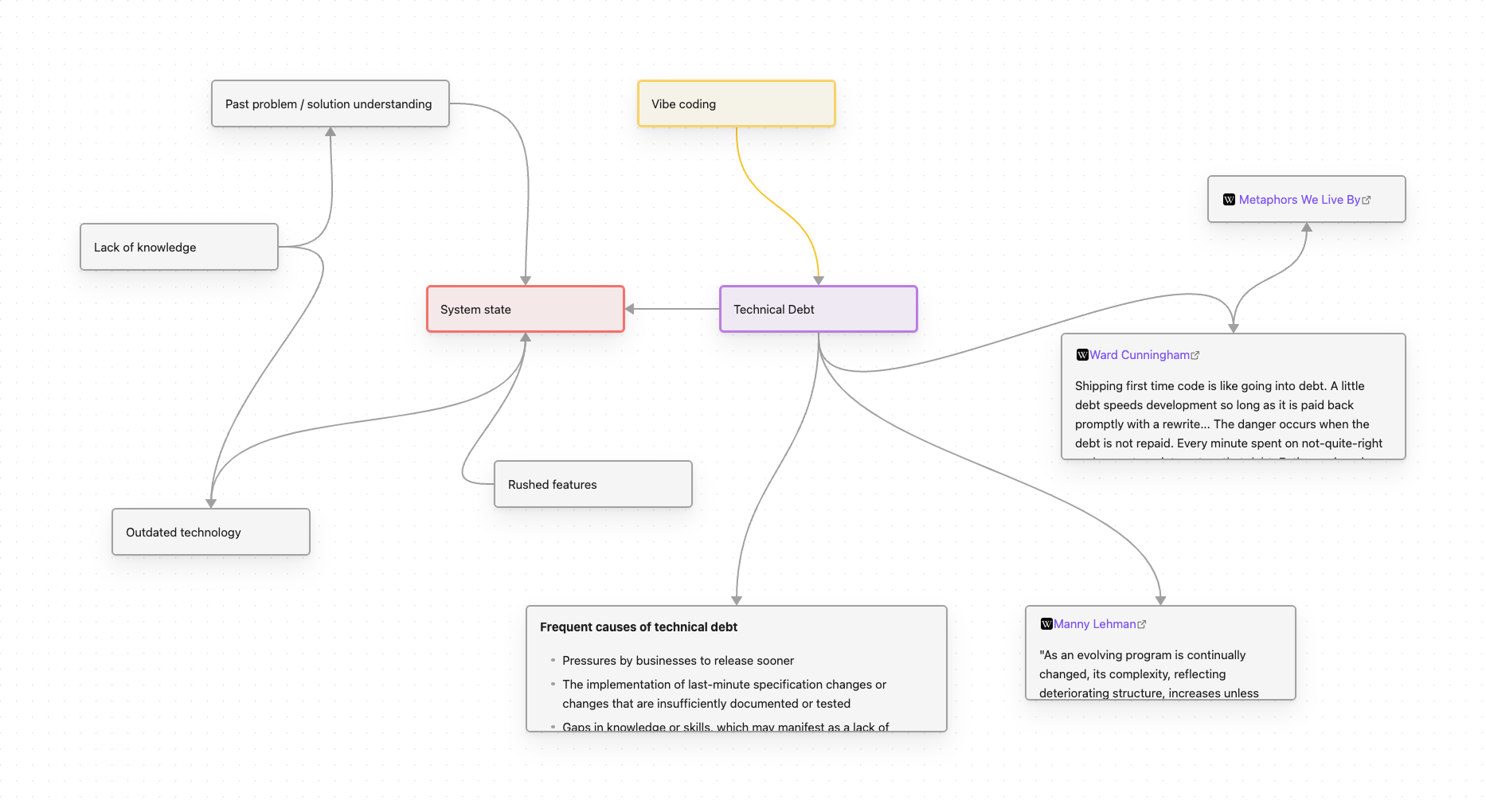
Note: as some other articles on this blog, this is a living document that will change in time.
Quick attempt
I think everyone would agree that well written software should have the following attributes.
- It does what it is supposed to do,
- It does not contain defects or problems,
- It is easy to read, maintain, and extend.
While true and well intentioned, this list expresses what I meant with abstract and prone to subjective perception.
Detailed approach
Even though (I find) the standards can be abstract and overly dry, the “Product quality model” of the “ISO/IEC 25010:2011” pretty well defines the attributes.
Aside the specialised ISO audits, I think with a pragmatic approach such attributes can be measured and improved.
Most of these can be regarded as non-functional attributes, and only the first addresses the functional requirements that arguably brings value to a software product. On the other hand the product worth can quickly erode if the other attributes are not covered as well. This is important for everyone involved to understand, which can be especially hard for non-technical stakeholders.
Here’s the list with notes and potential ways to measure and improve each.
Functional suitability
- Functional completeness
- Functional correctness
- Functional appropriateness – how well specified tasks and objectives can be accomplished
Notes
This is the only (!) set of attributes that addresses the fulfilment of functional requirements, even if these are the ones that arguably bring value to a software product. On the other hand the product worth quickly erodes if the later attributes are not covered as well. This is important for all the stakeholders to understand. (I know I am repeating myself on this one)
Measuring
This can be measured with manual and automated functional testing, fulfilment of acceptance criteria, and user feedback.
Apart from bug reports, in practically all systems I worked with, this could not be followed nor measured in operation.
Improving
Based on user feedback, bug reports, and internally measured usage KPIs.
- Time behaviour – the response and processing times, and throughput rates of a product or system
- Resource utilisation
- Capacity
Measure
The performance can be measured by performance testing and resource monitoring during those tests. Of course, operational monitoring will also bring insights, but this is in most cases too late.
Improving
Static code analysis tools can help, but profiling is still irreplaceable to improve.
Compatibility
- Co-existence
- Interoperability
Notes
This becomes extremely important in system architecture and large systems.
Measure
A set of questions that can help evaluate a system are:
- Is there a very specific set of requirements for deployment?
- How about operational requirements?
- Does the system have its own way of integrating with other systems, unlike the others?
With the container and serverless deployment and execution models, the co-existence becomes less of a problem, where the performance efficiency becomes important.
Improve
Interoperability is all about the API design, choreography/orchestration, and system openness. Smart endpoints and dumb pipes principle applies here as well.
Usability
- Appropriateness recognisability – how well can the user recognise whether a product or system is appropriate for their needs
- Learnability
- Operability
- User error protection
- User interface aesthetics
- Accessibility
This set of attributes is oriented to measure the fit with the end user. Software engineers (architects as well) are notoriously bad at this, and cooperating with UX/UI designers/engineers is crucial.
Measure
This is somewhat dependent on user technical orientation, subjective relationship to the product and previous familiarity. There are tools and platforms like UserTesting or Accessibility Insights that have defined a clear set of measurements (no affiliation or promotion, just the ones I am aware of).
Improve
Align the product implementation to the feedback and measurements. Introduce UX/UI design if not present. Introduce accessibility experts. Promote disability inclusion.
Reliability
- Maturity
- Availability
- Fault Tolerance (recovery)
- Recoverability (data)
Notes
This is about system design, deployment and operations models, network and product configuration.
Measure
Documenting your system with reliability block diagrams and performing fault tree analysis.
Improve
Chaos Monkey, redundant deployment, reduced dependencies.
Security
- Confidentiality – authorisation
- Integrity
- Non-repudiation – how well actions or events can be proven to have taken place
- Accountability
- Authenticity
Notes
Too often, this is taken as an afterthought, but is absolutely essential in having a system run properly and preserve the data as intended.
Measure
Security audits, code analysis, penetration testing, bounty programmes. Identify critical business data and business risks.
Improve
Use coding standards, especially take care of potential attack vectors and keep the attack surface as low as possible. Do not expose to the internet anything that is not absolutely needed.
Maintainability
- Modularity
- Reusability
- Analysability
- Modifiability
- Testability
Notes
Again, too often, this is taken as an afterthought, but is absolutely essential in building a sustainable system. This will have a hard impact on time to market, especially in the long run.
Measure
Code test coverage, code audit, pull requests, documentation (!), architecture, static code analysis, profiling.
Improve
Increase code test coverage, create unit tests, run tests in CI/CD, do code reviews, run
Portability
- Adaptability
- Installability
- Replaceability
Notes
Again, too often, this is taken as an afterthought, but is absolutely essential in building a sustainable system. This will have a hard impact on time to market.
Measure
Are the components using standard mechanisms of integration and
If you have a mobile app in the stack – what is the device and operating system compatibility.
Improve
Increase code test coverage, create unit tests, run tests in CI/CD, do code reviews.
Further reading
https://martinfowler.com/
W3C Web Accessibility Initiative (WAI).
Fault Tree Analysis (Wikipedia)
Hexagonal architecture