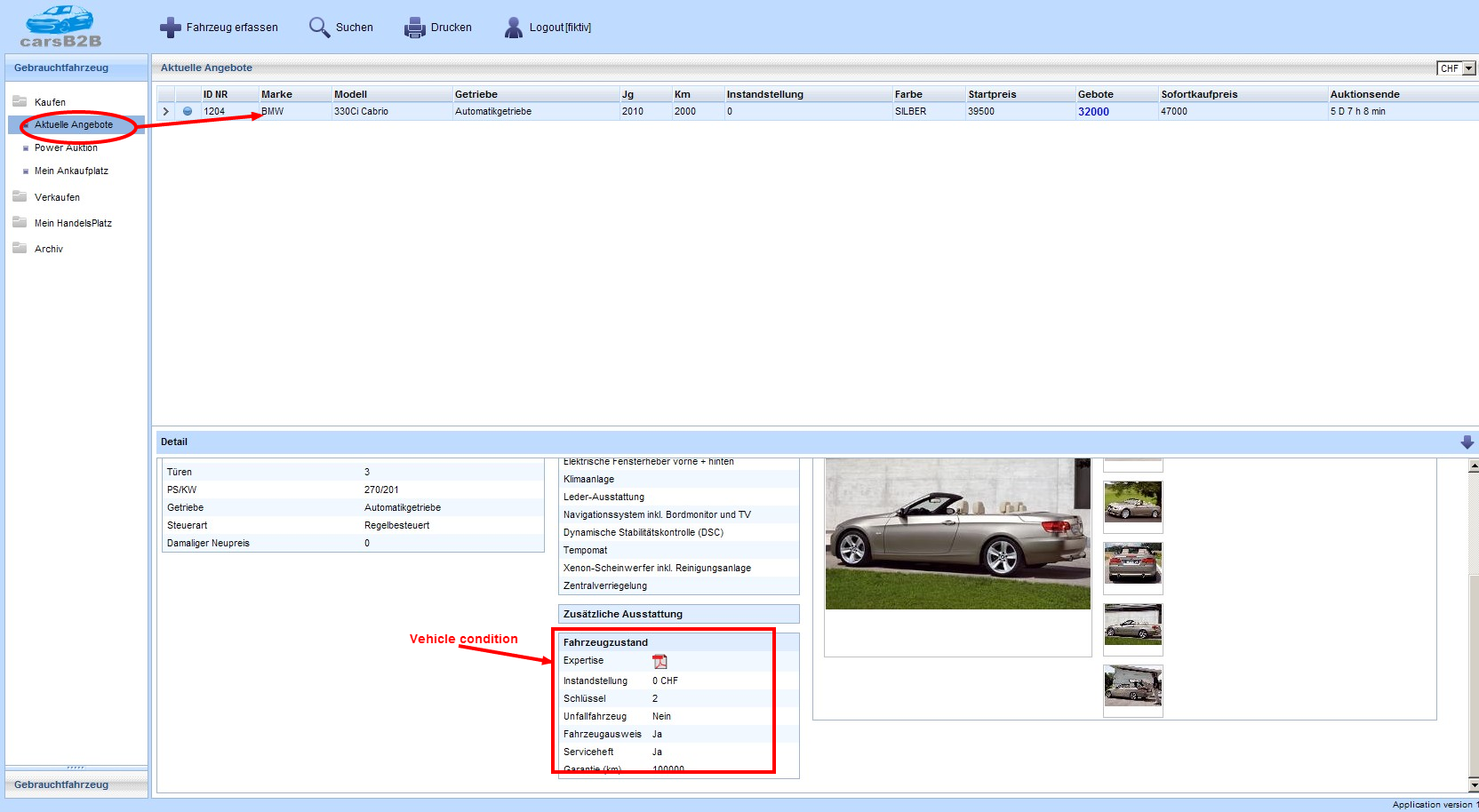
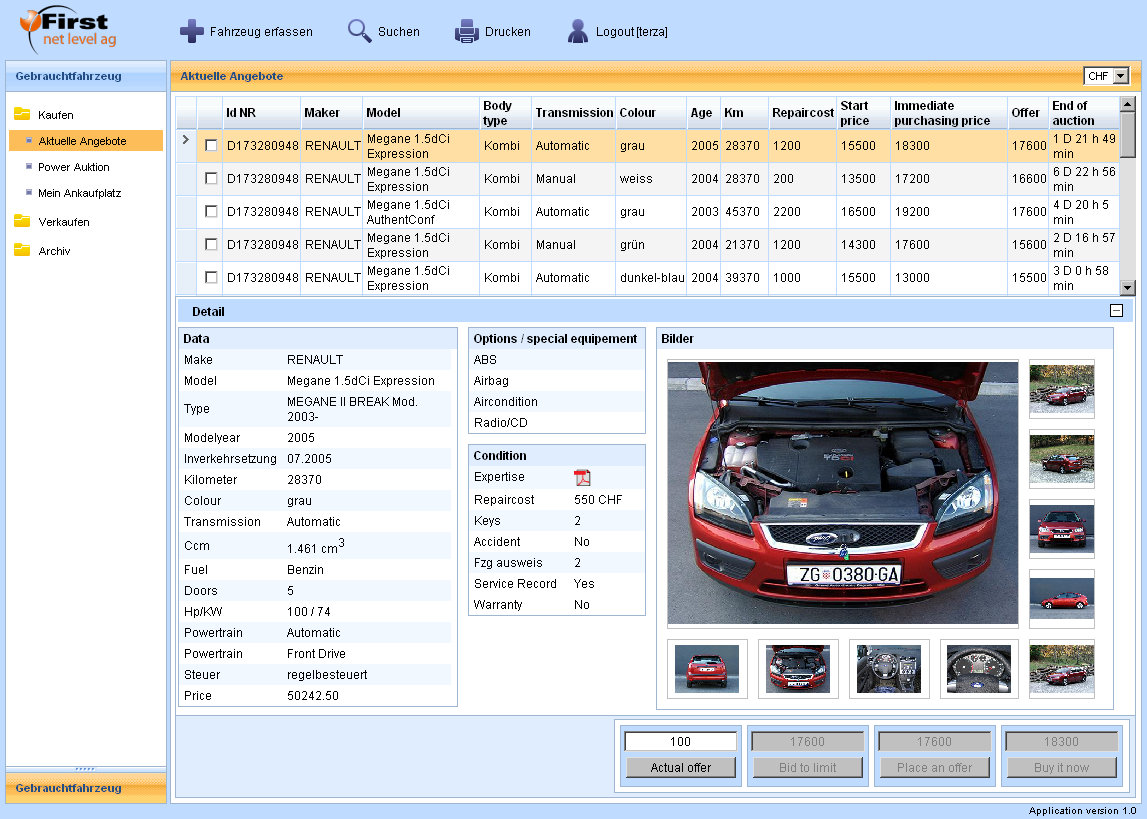
During 2007 and 2008 I worked on a document analysis tool called “Matchpoint”.
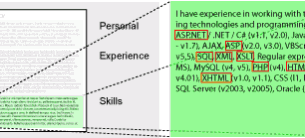
The idea is to parse the document by identifying content blocks and then find certain keywords within the context. The document is tagged based on the found information.



I did the software architecture first, creating the concepts, entities and relations,and identifying crucial parts of the system.

The heart of the system is the parsing engine that identifies segments of document, for example education, experience, and so on. All the permutations of the segments are used, and the one that matches the most segments is selected for further analysis. Each of the recognized segments is then searched for the keywords. Each keyword has appropriate tags assigned, and this way the document is in the end tagged.
Since the algorithm has to analyze documents in different languages, using semantic algorithms seemed a bit too complicated, so I went with regular expressions.

The documents can be emailed or uploaded by FTP to the web server, where is a Windows service monitoring configured folder. A .NET console application is then run to convert document to plain text using IFilters, and then to run the analysis, and upload the data to the Microsoft SQL Server database in the end.
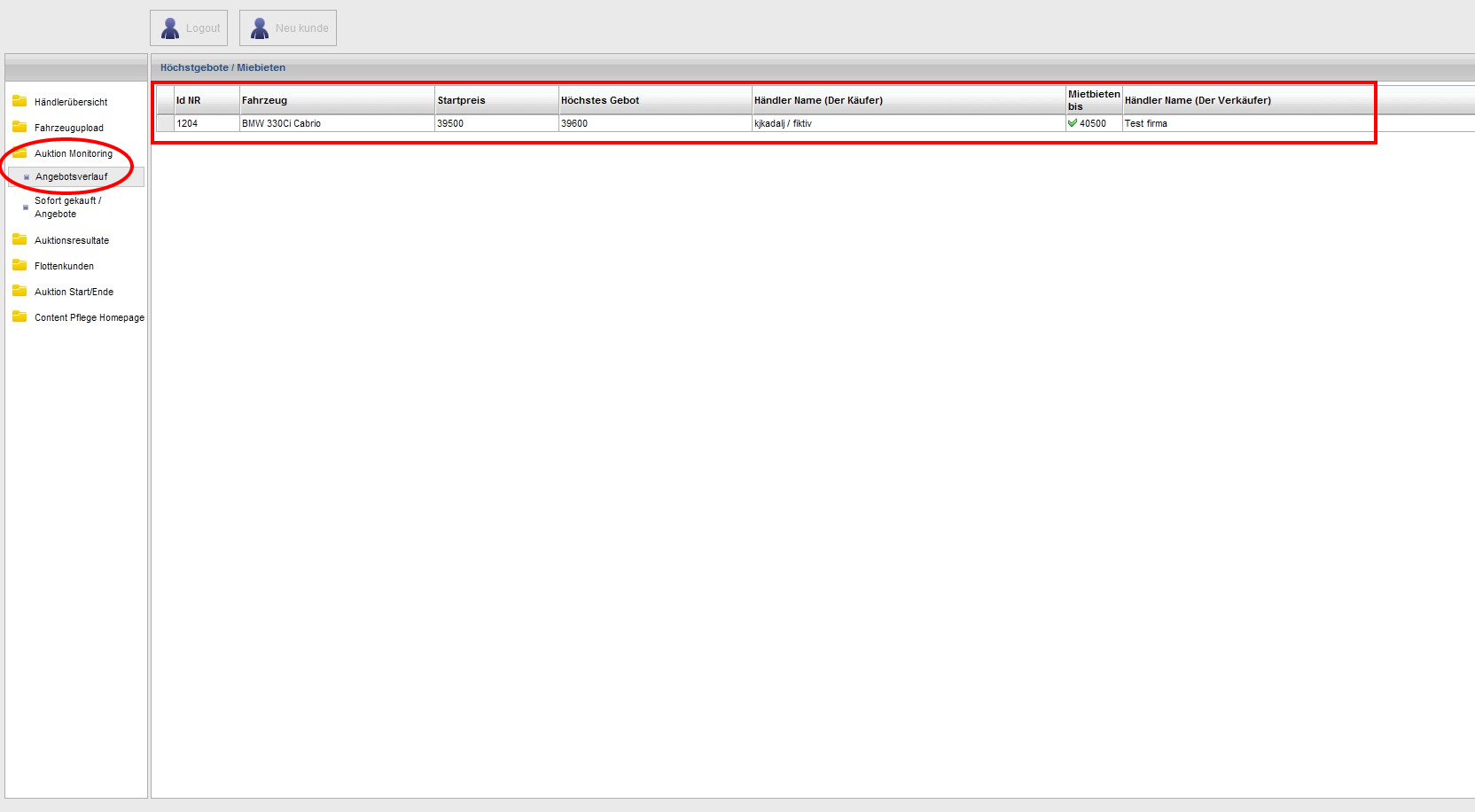
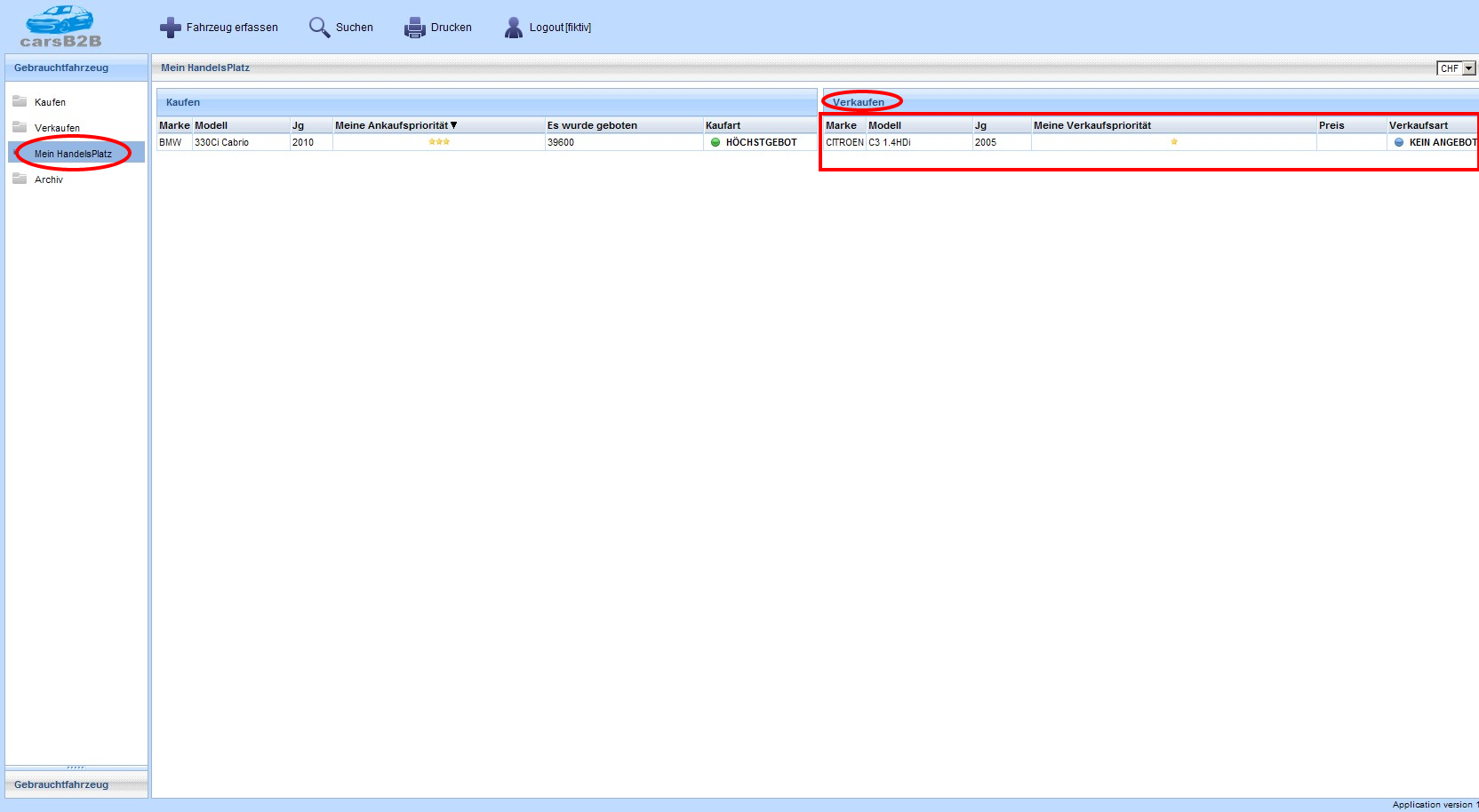
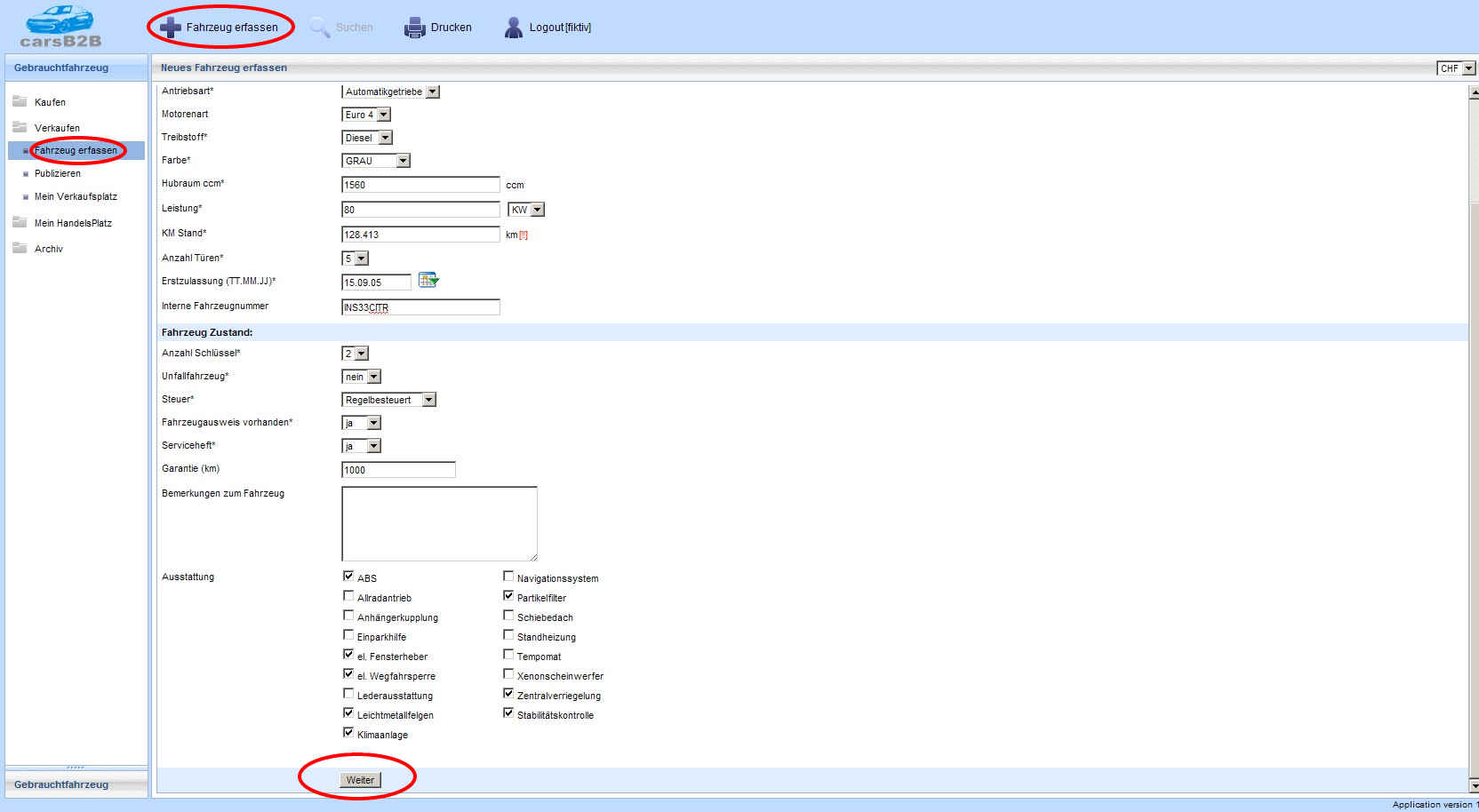
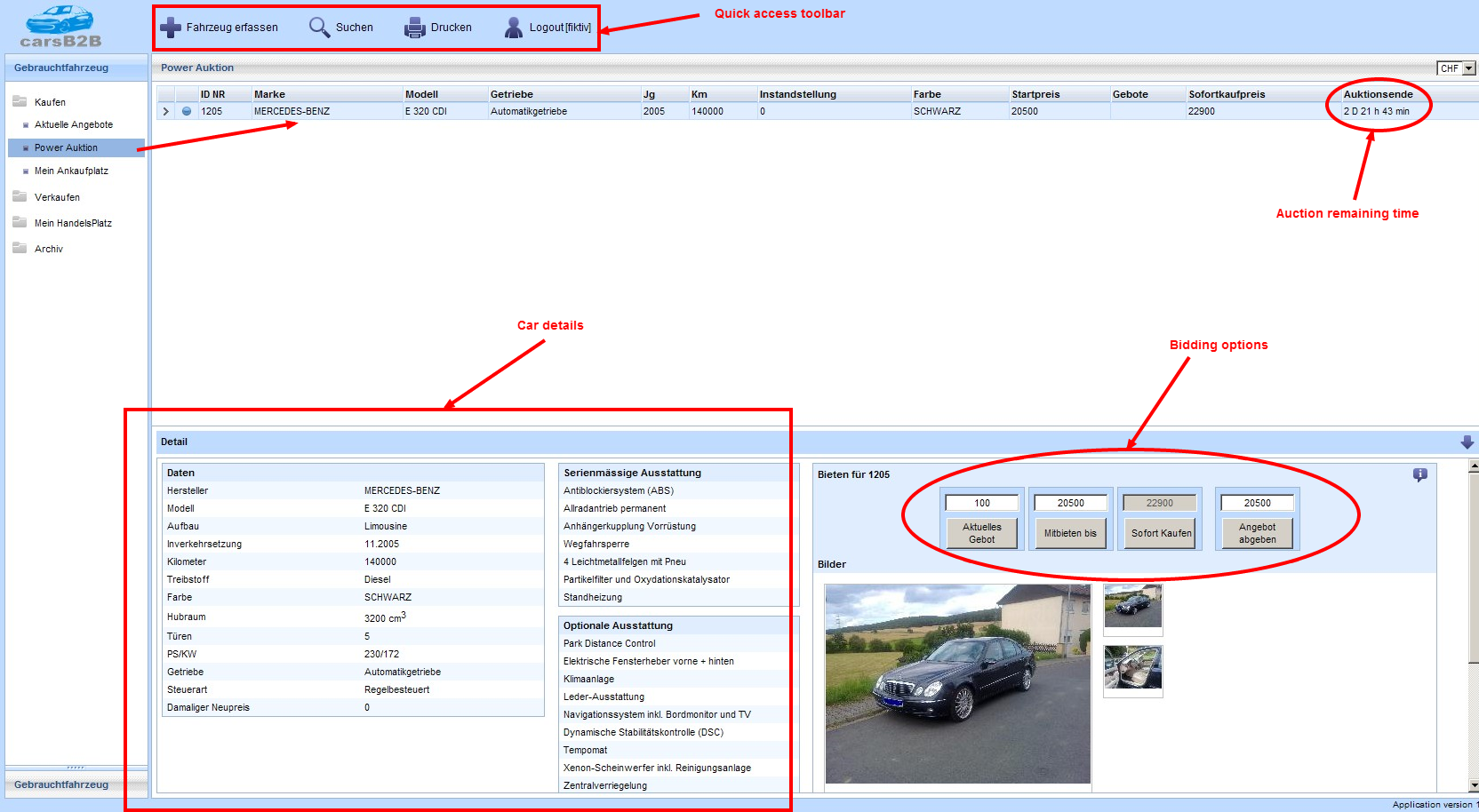
Users can use a web application built on ASP.NET Web Forms to search and view indexed documents.